Dernière mise à jour: 14.08.2017
Nous pouvons transmettre des données aux requêtes via des variables. Et nous pouvons également recevoir des données résultant de requêtes sur des variables. Par exemple, lors d'une sélection dans des tables à l'aide de la commande SELECT, nous pouvons récupérer des données dans une variable en utilisant la syntaxe suivante :
SELECT @variable_1 = spécification colonne_1, @variable_2 = spécification colonne_2, ....................................... @ variable_N = spécification colonne_N
De plus, dans une instruction SET, la valeur attribuée à une variable peut également être le résultat d'une instruction SELECT.
Par exemple, disons que nous avons les tableaux suivants :
CREATE TABLE Products (Id INT IDENTITY PRIMARY KEY, ProductName NVARCHAR(30) NOT NULL, Manufacturer NVARCHAR(20) NOT NULL, ProductCount INT DEFAULT 0, Price MONEY NOT NULL); CREATE TABLE Clients (Id INT IDENTITY PRIMARY KEY, FirstName NVARCHAR(30) NOT NULL) ; CREATE TABLE Orders (Id INT IDENTITY PRIMARY KEY, ProductId INT NOT NULL REFERENCES Products(Id) ON DELETE CASCADE, CustomerId INT NOT NULL REFERENCES Customers(Id) ON DELETE CASCADE, CreatedAt DATE NOT NULL, ProductCount INT DEFAULT 1, Price MONEY NOT NULL );
Nous utilisons des variables lors de la récupération des données :
DÉCLARE @maxPrice MONEY, @minPrice MONEY, @dif MONEY, @count INT SET @count = (SELECT SUM(ProductCount) FROM Orders); SELECT @minPrice=MIN(Price), @maxPrice = MAX(Price) FROM Products SET @dif = @maxPrice - @minPrice ; PRINT "Total vendu : " + STR (@count, 5) + " article(s)" ; PRINT "Différence entre le prix maximum et minimum : " + STR (@dif)
Dans ce cas, la variable @count contiendra la somme de toutes les valeurs de la colonne ProductCount de la table Commandes, c'est-à-dire le nombre total de produits vendus.
Les variables @min et @max stockent respectivement les valeurs minimales et maximales de la colonne Prix de la table Produits, et la variable @dif stocke la différence entre ces valeurs. Et pareil valeurs simples, les variables peuvent également participer aux opérations.
Autre exemple :
DÉCLARE @sum MONEY, @id INT, @prodid INT, @name NVARCHAR(20); DÉFINIR @id=2 ; SELECT @sum = SUM(Orders.Price*Orders.ProductCount), @name=Products.ProductName, @prodid = Products.Id FROM Orders INNER JOIN Products ON ProductId = Products.Id GROUP BY Products.ProductName, Products.Id HAVING Products .Id=@id PRINT "Produit " + @name + " vendu pour le montant de " + STR (@sum)
Ici, les données récupérées de deux tables Products et Orders sont regroupées par colonnes Id et ProductName de la table Products. Les données sont ensuite filtrées par la colonne Id de Products. Et les données extraites se retrouvent dans les variables @sum, @name, @prodid.
Dans ce document, nous examinerons bases de la programmation en langage T-SQL, nous découvrirons de quel type de langage il s'agit, quelles sont ses capacités de base, quelles constructions il inclut et, bien sûr, au cours de tout cela, je fournirai des exemples de code.
Et je voudrais commencer par le fait que sur ce site vous et moi avons déjà consacré pas mal de matériel au langage SQL et notamment à son extension Transact-SQL ( Comment comprenez-vous que T-SQL est une abréviation de Transact-SQL). Et nous avons même compilé un petit guide pour les débutants sur langue donnée et, bien sûr, nous avons examiné de nombreux exemples, mais en tant que telle programmation en T-SQL, par exemple, les variables, les constructions conditionnelles, les commentaires, nous avons abordé, mais ne nous sommes pas concentrés sur cela. Mais comme nous avons un site pour les programmeurs débutants, j'ai décidé de consacrer ce matériel à ces bases.
Langage de programmation T-SQL
Transact-SQL (T-SQL) est une extension du langage SQL de Microsoft et est utilisé dans Serveur SQL pour la programmation de bases de données.
SQL Server comprend de nombreuses constructions, composants et fonctions qui étendent les capacités du langage SQL standard ANSI, y compris la programmation classique, qui diffère de l'écriture de requêtes conventionnelle.
Et aujourd'hui, nous examinerons cette partie des bases du langage T-SQL, qui implique l'écriture de code pour implémenter certaines fonctionnalités ( par exemple, dans une procédure ou une fonction), et pas seulement une requête de base de données.
Variables en T-SQL
Et nous commencerons par les variables, elles sont nécessaires pour stocker certaines données temporaires que nous devons conserver pendant un certain temps puis utiliser.
Il existe deux types de variables dans T-SQL : locales et globales. Les variables locales n'existent que dans la session au cours de laquelle elles ont été créées, tandis que les variables globales sont utilisées pour obtenir des informations sur le serveur SQL ou des informations changeantes dans la base de données.
Les variables locales sont déclarées à l'aide du mot-clé DÉCLARER et commence par le signe @ . Comme dans de nombreux langages de programmation, les variables dans T-SQL doivent avoir un type de données spécifique. Il existe de nombreux types de données dans SQL Server ; nous les avons examinés en détail dans l'ouvrage de référence que j'ai mentionné juste au-dessus.
Vous pouvez utiliser les commandes pour attribuer une valeur à une variable ENSEMBLE ou Sélectionner.
Comme je l'ai déjà dit, les variables globales sont nécessaires pour obtenir des informations sur le serveur ou la base de données. Par exemple, les variables globales dans SQL Server incluent :
- @@ROWCOUNT – stocke le nombre d'enregistrements traités par la commande précédente ;
- @@ERROR – renvoie le code d'erreur de la dernière commande ;
- @@SERVERNAME — nom du serveur SQL local ;
- @@VERSION - numéro Versions SQL Serveur;
- @@IDENTITY est la dernière valeur du compteur utilisée dans l'opération d'insertion ( insérer).
Maintenant, à titre d'exemple, créons deux variables avec le type de données INT, attribuons-leur des valeurs, la première à l'aide de la commande SET et la seconde à l'aide de la commande Select, puis affichons simplement ces valeurs, et affichons également la valeur du @@VERSION variable, c'est-à-dire . Découvrez la version du serveur SQL.
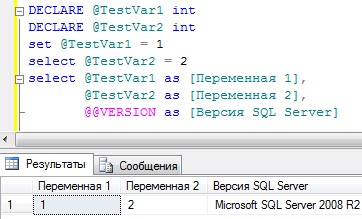
DECLARE @TestVar1 INT DECLARE @TestVar2 INT SET @TestVar1 = 1 SELECT @TestVar2 = 2 SELECT @TestVar1 AS [Variable 1], @TestVar2 AS [Variable 2], @@VERSION AS [Version SQL Server]
Forfaits
Package en T-SQL- ce sont des commandes ou des instructions SQL qui sont combinées en un seul groupe et le serveur SQL les compilera et les exécutera dans leur ensemble.
Afin de faire comprendre au serveur SQL que vous transmettez un lot de commandes, vous devez spécifier le mot-clé ALLER après toutes les commandes que vous souhaitez combiner dans un package.
Les variables locales ne seront visibles que dans le package dans lequel elles ont été créées, c'est-à-dire Vous ne pourrez plus accéder à la variable une fois le package terminé.
Disons que si l'exemple que nous avons utilisé ci-dessus est combiné dans un package et que nous essayons ensuite d'obtenir les valeurs des variables, alors nous obtiendrons ce qui suit :

Ceux. on voit que nous avons une erreur due au fait que la variable @TestVar1 n'est pas déclarée.
Conditions
Ces constructions impliquent du branchement, c'est-à-dire Selon que certaines conditions sont remplies ou non, les instructions T-SQL changeront de direction.
SI… Ailleurs
Cette construction existe, probablement dans tous les langages de programmation, elle consiste à vérifier si les conditions sont remplies et si toutes les vérifications sont réussies, alors la commande qui suit est exécutée, sinon, alors rien n'est exécuté, mais vous pouvez spécifier le mot clé ELSE puis dans dans ce cas, les opérateurs spécifiés seront exécutés après ce mot.

DECLARE @TestVar1 INT DECLARE @TestVar2 VARCHAR(20) SET @TestVar1 = 5 IF @TestVar1 > 0 SET @TestVar2 = "Supérieur à 0" ELSE SET @TestVar2 = "Moins de 0" SELECT @TestVar2 AS [Valeur TestVar1]
SI EXISTE
Cette construction permet de déterminer la présence d'enregistrements définis par une condition. Par exemple, nous voulons savoir s'il y a certains enregistrements dans la table et lorsque la première correspondance est détectée, le traitement des commandes s'arrête. C'est essentiellement la même chose que COUNT(*) > 0.
Par exemple, nous voulons vérifier s'il y a des enregistrements avec une valeur d'identifiant >=0 dans la table test_table, et sur cette base, nous déciderons comment procéder.

DECLARE @TestVar VARCHAR(20) IF EXISTS(SELECT * FROM test_table WHERE id > = 0) SET @TestVar = "Il y a des enregistrements" ELSE SET @TestVar = "Il n'y a aucun enregistrement" SELECT @TestVar AS [ Disponibilité des dossiers]
CAS
Cette construction est utilisée conjointement avec l'instruction select et est destinée à remplacer l'utilisation répétée de la construction IF. C'est utile dans les cas où vous devez vérifier une variable ( ou sur le terrain) pour la présence de certaines valeurs.

DECLARE @TestVar1 INT DECLARE @TestVar2 VARCHAR(20) SET @TestVar1 = 1 SELECT @TestVar2 = CASE @TestVar1 WHEN 1 THEN "Un" WHEN 2 THEN "Deux" ELSE "Inconnu" END SELECT @TestVar2 AS [Numéro]
DÉBUT...FIN
Cette construction est nécessaire pour créer un bloc de commandes, c'est-à-dire par exemple, si nous voulions exécuter non pas une commande après le bloc IF, mais plusieurs, alors nous devrions écrire toutes les commandes à l'intérieur du bloc BEGIN...END.
Modifions notre exemple précédent ( à propos de SI EXISTE) de sorte que s'il y a des enregistrements id > = 0 dans la table test_table, en plus d'attribuer une valeur à la variable @TestVar, nous effectuerons également une mise à jour, c'est-à-dire mettre à jour certaines données dans la même table et afficher également le nombre de lignes que nous avons mises à jour à l'aide de la variable globale @@ROWCOUNT.

DECLARE @TestVar1 VARCHAR(20) DECLARE @TestVar2 INT SET @TestVar2 = 0 IF EXISTS(SELECT * FROM test_table WHERE id > = 0) BEGIN SET @TestVar1 = "Les enregistrements existent" UPDATE test_table SET column1 = 5 WHERE id > = 0 SET @TestVar2 = @@ROWCOUNT END ELSE SET @TestVar1 = "Aucun enregistrement" SELECT @TestVar1 AS [Enregistrements présents], @TestVar2 AS [Lignes affectées :]
Boucles T-SQL
Si nous parlons de boucles en général, elles sont nécessaires pour répéter plusieurs fois l'exécution des commandes. Il y a une boucle dans T-SQL PENDANT que avec condition préalable, cela signifie que les commandes démarreront et seront répétées jusqu'à ce que la condition avant le début de la boucle soit remplie, l'exécution de la boucle peut également être contrôlée à l'aide de mots-clés CASSER Et CONTINUER.
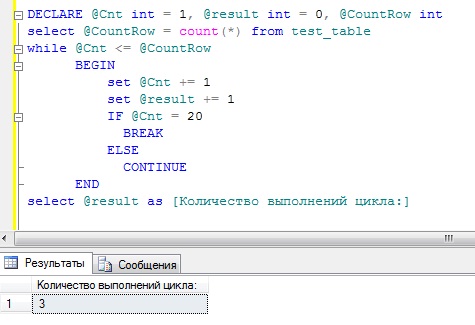
DECLARE @Cnt INT = 1, @result INT = 0, @CountRow INT SELECT @CountRow = COUNT(*) FROM test_table WHILE @Cnt<= @CountRow BEGIN SET @Cnt += 1 SET @result += 1 IF @Cnt = 20 BREAK ELSE CONTINUE END SELECT @result AS [Количество выполнений цикла:]
DANS dans cet exemple Bien entendu, nous déclarons d’abord les variables ( Nous initialisons immédiatement Cnt et result, de cette façon vous pouvez définir les valeurs des variables à partir de SQL Server 2008). Ensuite, nous découvrons combien de lignes il y a dans la table test_table et après cela nous vérifions si le nombre de lignes dans la table est supérieur ou égal à notre compteur, puis nous entrons dans notre boucle de test. Dans la boucle, nous augmentons la valeur du compteur, écrivons le résultat et vérifions à nouveau, si notre compteur a déjà atteint la valeur 20, alors nous le forcerons à se terminer, sinon, nous le laisserons continuer jusqu'à ce que la valeur du compteur devienne supérieure ou égale. au nombre de lignes du tableau ou jusqu'à 20 s'il y a plus de lignes dans le tableau.
Commentaires
Ils sont nécessaires pour expliquer et prendre des notes dans le code, car si le code est volumineux et complexe, après un certain temps, vous risquez simplement d'oublier pourquoi exactement cela se produit et pourquoi vous avez écrit telle ou telle section de code. Dans T-SQL, il existe des commentaires sur une seule ligne (-Text) et sur plusieurs lignes (/*Text*/).

Commandes T-SQL
ALLER À
À l’aide de cette commande, vous pouvez parcourir le code jusqu’à une étiquette spécifiée. Par exemple, il peut être utilisé lorsque l'on souhaite faire une sorte de boucle, mais sans le while.

DECLARE @Cnt INT = 0 Label : --Définissez le label SET @Cnt += 1 --Ajoutez 1 à la variable si @Cnt< 10 GOTO Metka --Если значение меньше 10, то переходим к метке SELECT @Cnt AS [Значение Cnt =]
ATTENDRE
Une commande peut suspendre l'exécution du code pendant un certain temps ou jusqu'à une heure spécifiée. Paramètre RETARD fait une pause d'une durée donnée, et TEMPS met le processus en pause jusqu'à l'heure spécifiée. Les valeurs des paramètres sont spécifiées au format hh:mi:ss

RETOUR
Cette commande permet de quitter sans condition une requête ou une procédure. RETURN peut être utilisé à tout moment pour quitter une procédure, un lot ou un bloc d'instructions. Tout ce qui vient après cette commande n'est pas exécuté.

DECLARE @Cnt INT = 1, @result varchar(15) /*Si la valeur de Cnt est inférieure à 0, alors les commandes suivantes ne seront pas exécutées et vous ne verrez pas la colonne [Result:]*/ IF @Cnt< 0 RETURN SET @result = "Cnt больше 0" SELECT @result AS [Результат:]
IMPRIMER
Pour envoyer un message de service, vous pouvez utiliser la commande IMPRIMER. Dans Management Studio, ce message apparaîtra dans l'onglet Messages ( Messages).

DECLARE @Cnt INT = 10, @TestVar varchar(100) IF @Cnt > 0 SET @TestVar = "La valeur de la variable Cnt est supérieure à 0 et égale à " + CAST (@Cnt AS VARCHAR(10)) Sinon SET @TestVar = "La valeur de la variable Cnt est inférieure à 0 et égale à " + CAST (@Cnt AS VARCHAR(10)) PRINT @TestVar
Transactions
Transaction est une commande ou un bloc de commandes qui se termine avec succès ou est annulé dans son ensemble. En d’autres termes, si une commande ou une instruction au sein d’une transaction échoue, alors tout ce qui a été traité avant elle est également annulé, même si les commandes précédentes se sont terminées avec succès.
Ce mécanisme est nécessaire pour garantir l'intégrité des données, c'est-à-dire Disons que vous disposez d'une procédure qui transfère de l'argent d'un compte à un autre, mais qu'une situation peut survenir dans laquelle l'argent a été retiré du compte mais n'est pas allé vers un autre compte. Par exemple, l'instruction SQL qui retire de l'argent a fonctionné, mais lors de l'exécution de l'instruction qui a déposé de l'argent, une erreur s'est produite, en d'autres termes, l'argent a été retiré et simplement perdu. Pour éviter cela, toutes les instructions SQL sont écrites dans une transaction, puis si une telle situation se produit, toutes les modifications seront annulées, c'est-à-dire l'argent sera restitué sur votre compte.

Découvrez ce que nous avons dans la table (id = IDENTITY) SELECT * FROM test_table --Démarrez la transaction BEGIN TRAN --Mettez d'abord à jour toutes les données UPDATE test_table SET column1 = column1 - 5 --Ensuite, ajoutez simplement des lignes avec de nouvelles valeurs INSERT INTO test_table SELECT column1 FROM test_table --S'il y a une erreur, alors annulez tout IF @@error != 0 BEGIN ROLLBACK TRAN RETURN END COMMIT TRAN --Voir ce qui s'est passé SELECT * FROM test_table
Dans cet exemple, si nous avions une erreur au moment de l'ajout des données (INSERT), alors la MISE À JOUR serait annulée.
Gestion des erreurs - Construction TRY...CATCH
Lors de l'exécution du code T-SQL, une situation inattendue peut survenir, c'est-à-dire une erreur qui doit être traitée. Dans SQL Server, à partir de SQL Server 2005, il existe une construction telle que ESSAYEZ...ATTRAPEZ, qui peut suivre l'erreur.

BEGIN TRY DECLARE @TestVar1 INT = 10, @TestVar2 INT = 0, @result INT SET @result = @TestVar1 / @TestVar2 END TRY BEGIN CATCH SELECT ERROR_NUMBER() AS [Numéro d'erreur], ERROR_MESSAGE() AS [Description de l'erreur] END ATTRAPER
Dans cet exemple, une situation s'est produite dans laquelle une division par zéro se produit ( Comme vous le savez, on ne peut pas diviser par 0) et comme notre bloc de code a été placé dans une construction TRY, nous avons obtenu une exception dans laquelle nous obtenons simplement le numéro d'erreur et sa description.
Je pense que cela suffit pour les bases, si vous souhaitez étudier plus en détail toutes les constructions du langage T-SQL, je vous recommande de lire mon livre « The T-SQL Programmer's Way », qui traite déjà du langage T-SQL dans plus de détails, c'est tout pour moi, bonne chance !
Définition des valeurs des variables
Actuellement en Langage SQL Il existe deux manières de définir la valeur d'une variable : à cet effet, vous pouvez utiliser l'instruction SELECT ou SET. En termes de fonctionnalité, ces instructions fonctionnent presque de la même manière, sauf que l'instruction SELECT vous permet d'obtenir la valeur d'affectation d'origine à partir de la table spécifiée dans l'instruction SELECT.
L'instruction SET est généralement utilisée pour définir les valeurs des variables sous une forme plus courante dans les langages procéduraux. Des exemples typiques d'utilisation de cet opérateur sont les suivants :
ENSEMBLE @b = @a * 1,5
Notez que toutes ces instructions effectuent des opérations d'affectation directe, soit en utilisant des valeurs explicites, soit d'autres variables. Il n'est pas possible d'attribuer à l'aide de l'instruction SET valeur variable, obtenu sur demande ; la requête doit être exécutée séparément et seulement après cela, le résultat résultant peut être attribué à l'aide de l'instruction SET. Par exemple, une tentative d'exécution d'une telle instruction provoque une erreur :
SET @c = COUNT(*) DEPUIS Ville
et l'instruction suivante s'exécute avec succès :
SET @c = (SELECT COUNT(*) FROM Ville)
Instruction SELECT généralement utilisé pour attribuer des valeurs aux variables lorsque la source des informations à stocker dans la variable est une requête. Par exemple, les actions effectuées dans le code ci-dessus sont beaucoup plus couramment implémentées à l'aide d'une instruction SELECT :
SELECT @c = COUNT(*) FROM Ville
Veuillez noter que ce code un peu plus clair (en particulier, il est plus concis, même s'il fait les mêmes actions).
Ainsi, il est possible de formuler la convention suivante généralement acceptée pour l'utilisation des deux opérateurs.
L'instruction SET est utilisée lorsqu'une simple opération d'affectation de variable doit être effectuée, c'est-à-dire si la valeur attribuée est déjà donnée explicitement sous la forme d'une valeur spécifique ou sous la forme d'une autre variable.
L'instruction SELECT est utilisée lorsque l'affectation d'une valeur à une variable doit être basée sur une requête.
Utilisation de variables dans Requêtes SQL
L'une des propriétés utiles de T-SQL est que les variables peuvent être utilisées dans des requêtes sans qu'il soit nécessaire de créer des chaînes dynamiques complexes intégrant des variables dans le code du programme. Dynamic SQL continue d'exister, mais une seule valeur peut être modifiée plus facilement, à l'aide d'une variable.
Partout où une expression peut être utilisée dans une requête, une variable peut également être utilisée. L'exemple suivant illustre l'utilisation d'une variable dans une clause WHERE :
DÉCLARE @IdProd int;
FIXER @IdProd = 1 ;
SÉLECTIONNER
Microsoft SQL Server possède un type de données spécial TABLE, sur la base duquel nous pouvons créer des variables de table, afin de les utiliser dans vos instructions et procédures, et aujourd'hui nous allons examiner ces variables, découvrir comment elles sont déclarées et quelles sont les caractéristiques de ces variables.
Description des variables de table MS SQL Server
Variables du tableau sont des variables avec un type de données TABLE spécial qui sont utilisées pour stocker temporairement l'ensemble de données résultant sous la forme de lignes de tableau. Ils sont apparus dans la version 2005 de SQL Server. Vous pouvez utiliser ces variables dans des procédures stockées, des fonctions, des déclencheurs et des packages SQL classiques. Les variables de table sont créées de la même manière que les variables normales en les déclarant avec l'instruction DECLARE.
Les variables de ce type sont conçues comme une alternative aux tables temporaires. Si nous parlons de savoir s'il est préférable d'utiliser des variables de table ou des tables temporaires, il n'y a pas de réponse claire. Les variables de table ont à la fois des avantages et des inconvénients. Par exemple, j'aime personnellement utiliser des variables de table car elles sont pratiques à créer ( ceux. déclarer) et il n'est pas nécessaire de penser à les supprimer ou à les effacer à la fin des instructions, puisqu'ils sont automatiquement effacés ( tout comme les variables régulières). Mais en même temps, il est préférable d'utiliser des variables de table uniquement lorsque vous souhaitez y stocker une petite quantité de données, sinon il est recommandé d'utiliser des tables temporaires.
Avantages des variables de table dans Microsoft SQL Server
- Les variables de table se comportent comme des variables locales. Ils ont un champ d'application précisément défini ;
- Les variables du tableau sont automatiquement effacées à la fin de l'instruction dans laquelle elles ont été définies ;
- Lors de l'utilisation de variables de table dans des procédures stockées, les recompilations se produisent moins souvent que lors de l'utilisation de tables temporaires ;
- Les transactions utilisant des variables TABLE se poursuivent uniquement pendant la mise à jour de la variable correspondante. Pour cette raison, les variables de table sont moins susceptibles d'être verrouillées et nécessitent moins de ressources pour tenir des journaux.
Inconvénients des variables de table dans MS SQL Server
- Les requêtes qui modifient les variables TABLE ne créent pas de plans de requête parallèles ;
- Les variables TABLE n'ont pas de statistiques de distribution et ne déclenchent pas de recompilations, il est donc recommandé de les utiliser pour un petit nombre de lignes ;
- Les variables de table ne peuvent pas être modifiées une fois créées ;
- Les variables de table ne peuvent pas être créées à l'aide d'une instruction SELECT INTO ;
- Les variables TABLE ne changent pas lors des annulations de transactions car elles ont une portée limitée et ne font pas partie des bases de données persistantes.
Exemples d'utilisation de variables de table dans Microsoft SQL Server
Passons maintenant à la pratique, et je tiens d'abord à préciser que mon serveur est Microsoft SQL Server 2016 Express, autrement dit, toutes les requêtes ci-dessous ont été exécutées sur cette version du SGBD.
Tout d'abord, créons une table de test et remplissons-la avec des données de test pour voir comment les variables de table peuvent être utilisées avec des tables normales.
CREATE TABLE TestTable(ProductId INT IDENTITY(1,1) NOT NULL, ProductName VARCHAR(50) NULL CONSTRAINT PK_TestTable PRIMARY KEY CLUSTERED (ProductId ASC)) GO INSERT INTO TestTable (ProductName) VALUES ("Ordinateur"), ("Moniteur") , ("Imprimante") GO SELECT * FROM TestTable

J'ai utilisé l'instruction CREATE TABLE pour créer la table TestTable, puis j'ai utilisé l'instruction INSERT en conjonction avec le constructeur de valeur de table VALUES pour ajouter des données à la table, puis j'ai utilisé l'instruction SELECT pour sélectionner dans la table nouvellement créée.
Déclarer une variable de table et l'utiliser
Dans cet exemple, nous allons déclarer une variable de table, y ajouter des données et effectuer une sélection parmi deux tables ( table variable et table régulière) avec syndicat.
Déclaration d'une variable de table DECLARE @TableVar TABLE(ProductId INT NOT NULL, Price MONEY NULL);

--Ajout de données à une variable de table INSERT INTO @TableVar (ProductId, Price) VALUES (1 500), (2 300), (3 200) --Utilisation d'une variable de table avec une jointure de données SELECT TTable.ProductId, TTable .ProductName , TVar.Price FROM @TableVar TVar LEFT JOIN TestTable TTable ON TVar.ProductId = TTable.ProductId
Création d'une variable de table avec une clé primaire, une contrainte UNIQUE et un index non clusterisé Cet exemple montre comment créer une clé primaire, des contraintes UNIQUE et des index non clusterisés sur des variables de table. La possibilité de créer un index non clusterisé est disponible depuis Versions Microsoft
SQL Serveur 2014.

Déclaration de variable de table DECLARE @TableVar TABLE(ProductId INT NOT NULL PRIMARY KEY, --Primary key ProductName VARCHAR(50) NOT NULL, Price MONEY NOT NULL, UNIQUE (ProductName, Price), --Constraint INDEX IX_TableVar NONCLUSTERED (Price) -- Index non clusterisé);
--Ajout de données à une variable de table INSERT INTO @TableVar (ProductId, ProductName, Price) VALUES (1, "Ordinateur", 500), (2, "Moniteur", 300), (3, "Imprimante", 200); --Sélection de données SELECT ProductName FROM @TableVar WHERE Prix > 200- Ceci conclut mon histoire sur les variables de table, si vous souhaitez étudier le langage T-SQL en détail, je vous recommande de lire mon livre « The T-SQL Programmer's Way », j'espère que le matériel vous a été utile, au revoir !
Programmation sur
T
SQL
Syntaxe et conventions T-SQL Règles de génération des identifiants Tous les objets dans SQL Server ont des noms (identifiants). Des exemples d'objets sont des tables, des vues, des procédures stockées, etc. Les identifiants peuvent comporter jusqu'à 128 caractères, y compris des lettres, _@$# et des chiffres.
Le premier caractère doit toujours être alphabétique. Les variables et les tables temporaires utilisent des schémas de dénomination spéciaux. Le nom de l'objet ne peut pas contenir d'espaces et ne peut pas être identique à un nom réservé
La norme ANSI SQL exige qu'un point-virgule soit placé à la fin de chaque instruction. Cependant, lors de la programmation en T-SQL, le point-virgule n'est pas requis.
Commentaires
Le langage T-SQL autorise deux styles de commentaires : ANCI et C. Le premier d'entre eux commence par deux tirets et se termine en fin de ligne :
Il s'agit d'un commentaire d'une seule ligne de style ANSI
Des commentaires de style ANSI peuvent également être insérés à la fin de la ligne de déclaration :
SELECT Nom de la ville – colonnes extraites
DE Ville – tableau des sources
OÙ IdCity = 1 ; -- limite de ligne
L'éditeur SQL peut appliquer et supprimer des commentaires sur toutes les lignes sélectionnées. Pour ce faire, sélectionnez les commandes appropriées dans le menu Modifier ou sur la barre d'outils.
Les commentaires de style C commencent par une barre oblique et un astérisque (/*) et se terminent par les mêmes caractères dans l'ordre inverse. Ce type de commentaire est mieux utilisé pour commenter des blocs de lignes, tels que des en-têtes ou des requêtes de test volumineuses.
multiligne
commentaires
L'un des principaux avantages des commentaires de style C est qu'ils peuvent exécuter des requêtes multilignes sans même les décommenter.
Forfaits T-SQL
Une requête est une seule instruction T-SQL et un lot en est un ensemble. La séquence entière d'instructions d'un paquet est envoyée au serveur depuis les applications clientes comme une seule unité solide.
SQL Server traite l'ensemble du package comme une unité de travail. La présence d'une erreur dans au moins une instruction rendra impossible l'exécution de l'intégralité du package. Dans le même temps, l'analyse ne vérifie pas les noms des objets et des schémas, puisque le schéma lui-même peut changer lors de l'exécution de l'instruction.
Le fichier de script SQL et la fenêtre de l'Analyseur de requêtes peuvent contenir plusieurs packages. Dans ce cas, tous les packages partagent des mots-clés de terminaison. Par défaut, ce mot-clé est GO et doit être le seul sur la ligne. Tous les autres caractères (même les commentaires) neutralisent le délimiteur de paquets.
Débogage de T-SQL
Lorsque l'éditeur SQL rencontre une erreur, il affiche la nature de l'erreur et le numéro de ligne dans le batch. En double-cliquant sur une erreur, vous pouvez accéder directement à la ligne correspondante.
Vers l'utilitaire de gestion Version studio SQL Server 2005 n'inclut pas le débogueur du langage T-SQL : il est inclus dans le package Visual Studio.
SQL Server propose plusieurs commandes pour faciliter le débogage des packages. En particulier, la commande PRINT envoie un message sans générer de jeu de résultats. La commande PRINT peut être utilisée pour suivre la progression d'un package. Lorsque l'analyseur de requêtes est en mode grille, exécutez le lot suivant :
SELECT Nom de la ville
DE Ville
OÙ IdCity = 1 ;
IMPRIMER "Point de contrôle" ;
L'ensemble de données résultant sera affiché dans une grille et comprendra une seule ligne. Parallèlement, le résultat suivant s'affichera dans l'onglet Messages :
(lignes traitées : 1)
Point de contrôle
Variables
Les variables T-SQL sont créées à l'aide de la commande DECLARE, qui présente la syntaxe suivante :
DÉCLARE @Variable_NameData_Type [,
@Variable_NameData_Type, ...]
Tous les noms de variables locales doivent commencer par le symbole @. Par exemple, pour déclarer une variable locale USStr qui stocke jusqu'à 16 caractères Unicode, vous pouvez utiliser les instructions suivantes:
DÉCLARER @USStr varchar (16)
Utilisé pour types de variables les données correspondent exactement à celles existantes dans les tableaux. Une commande DECLARE peut répertorier plusieurs variables séparées par des virgules. Plus précisément, l'exemple suivant crée deux variables entières a et b :
DÉCLARER
@aint,
@b entier
La portée des variables (c'est-à-dire leur durée de vie) s'étend uniquement au package actuel. Par défaut, les variables nouvellement créées sont vides Valeurs NULLES et doit être initialisé avant d'être inclus dans les expressions.
Définition des valeurs des variables
Actuellement, le langage SQL propose deux manières de définir la valeur d'une variable : vous pouvez utiliser l'instruction SELECT ou SET à cet effet. En termes de fonctionnalité, ces instructions fonctionnent presque de la même manière, sauf que l'instruction SELECT vous permet d'obtenir la valeur d'affectation d'origine à partir de la table spécifiée dans l'instruction SELECT.
L'instruction SET est généralement utilisée pour définir les valeurs des variables sous une forme plus courante dans les langages procéduraux. Des exemples typiques d'utilisation de cet opérateur sont les suivants :
ENSEMBLE @a = 1 ;
ENSEMBLE @b = @a * 1,5
Notez que toutes ces instructions effectuent des opérations d'affectation directe, soit en utilisant des valeurs explicites, soit d'autres variables. Vous ne pouvez pas utiliser l'instruction SET pour attribuer une valeur à une variable récupérée par une requête ; la requête doit être exécutée séparément et seulement après cela, le résultat résultant peut être attribué à l'aide de l'instruction SET. Par exemple, une tentative d'exécution d'une telle instruction provoque une erreur :
DÉCLARER @c int
SET @c = COUNT (*) DEPUIS Ville
SÉLECTIONNER @c
et l'instruction suivante s'exécute avec succès :
DÉCLARER @c int
SET @c = (SELECT COUNT (*) FROM Ville)
SÉLECTIONNER @c
L'instruction SELECT est généralement utilisée pour attribuer des valeurs aux variables lorsque la source des informations à stocker dans la variable est une requête. Par exemple, les actions effectuées dans le code ci-dessus sont beaucoup plus couramment implémentées à l'aide d'une instruction SELECT :
DÉCLARER @c int
SELECT @c = COUNT (*) FROM Ville
SÉLECTIONNER @c
Attention, ce code est un peu plus clair (notamment, il est plus concis, même s'il fait la même chose).
Ainsi, il est possible de formuler la convention suivante généralement acceptée pour l'utilisation des deux opérateurs.
L'instruction SET est utilisée lorsqu'une simple opération d'affectation de variable doit être effectuée, c'est-à-dire si la valeur attribuée est déjà donnée explicitement sous la forme d'une valeur spécifique ou sous la forme d'une autre variable.
- L'instruction SELECT est utilisée lorsque l'affectation d'une valeur à une variable doit être basée sur une requête.
Utilisation de variables dans les requêtes SQL
L'une des propriétés utiles de T-SQL est que les variables peuvent être utilisées dans des requêtes sans qu'il soit nécessaire de créer des chaînes dynamiques complexes intégrant des variables dans le code du programme. Dynamic SQL continue d'exister, mais une seule valeur peut être modifiée plus facilement, à l'aide d'une variable.
Partout où une expression peut être utilisée dans une requête, une variable peut également être utilisée. L'exemple suivant illustre l'utilisation d'une variable dans une clause WHERE :
DÉCLARE @IdProd int ;
FIXER @IdProd = 1 ;
SÉLECTIONNER
DU Produit
OÙ IdProd = @IdProd;
Variables système globales
SQL Server dispose de plus de trente variables globales sans paramètre définies et gérées par le système. Toutes les variables globales sont préfixées par deux caractères @. Vous pouvez extraire la valeur de n'importe lequel d'entre eux avec un simple Requête SELECT, comme dans l'exemple suivant :
SÉLECTIONNEZ @@CONNEXIONS
Cela utilise la variable globale @@CONNECTIONS pour récupérer le nombre de connexions à SQL Server depuis le démarrage du programme.
Parmi les variables système les plus couramment utilisées figurent les suivantes :
- @@ERROR - Contient le numéro d'erreur survenu lors de l'exécution de la dernière instruction T-SQL sur la connexion actuelle. Si aucune erreur n'est détectée, elle contient 0. La valeur de cette variable système est réinitialisée après l'exécution de chaque instruction successive. Si vous souhaitez enregistrer la valeur qu'elle contient, cette valeur doit être transférée vers une variable locale immédiatement après l'exécution de l'instruction pour laquelle le code d'erreur doit être stocké.
- @@IDENTITY - Contient la dernière valeur d'identité insérée dans la base de données à la suite de la dernière instruction INSERT. Si la dernière instruction INSERT n'a pas produit de valeur d'identité, la variable système @@IDENTITY contient NULL. Cette affirmation reste vraie même si la valeur d'identification manquante a été provoquée par un crash lors de l'exécution de l'instruction. Et si plusieurs opérations d'insertion sont effectuées à l'aide d'une seule instruction, seule la dernière valeur d'identification est attribuée à cette variable système.
- @@ROWCOUNT - L'une des variables système les plus utilisées. Renvoie des informations sur le nombre de lignes affectées par la dernière instruction. Généralement utilisé pour surveiller les erreurs autres que celles classées comme erreurs d’exécution. Par exemple, si un programme découvre qu'après avoir appelé une instruction DELETE avec une clause WHERE, le nombre de lignes affectées est nul, alors nous pouvons conclure que quelque chose d'inattendu s'est produit. Le message d'erreur peut alors être activé manuellement.
! Il convient de noter que depuis SQL Server 2000, les variables globales sont appelées fonctions. Le nom global a dérouté les utilisateurs, leur permettant de penser que la portée de ces variables était plus large que celle des variables locales. Les variables globales étaient souvent attribuées à tort à la capacité de stocker des informations, qu'elles soient incluses ou non dans le package, ce qui, bien entendu, n'était pas vrai.
Contrôles du flux de commandes. Constructions logicielles
Le langage T-SQL fournit la plupart des moyens procéduraux classiques pour contrôler la progression de l'exécution du programme, incl. conditions et boucles.
OpérateurSI. . . AUTRE
Déclarations SI. . .ELSE fonctionne dans T-SQL essentiellement de la même manière que dans tout autre langage de programmation. La syntaxe générale de cet opérateur est la suivante :
SI Expression logique
Instruction SQL I BEGIN Bloc d'instructions SQL END
Instruction SQL | BEGIN Bloc d'instructions SQL END]
Comme expression logique Presque toutes les expressions peuvent être spécifiées, dont le résultat entraîne le retour d'une valeur booléenne.
Il convient de noter que seule l'instruction qui suit immédiatement l'instruction IF (la plus proche de celle-ci) est considérée comme exécutée conformément à la condition. Au lieu d'une seule instruction, vous pouvez fournir l'exécution conditionnelle de plusieurs instructions en les combinant dans un bloc de code à l'aide de la construction BEGIN...END.
Dans l'exemple ci-dessous, la condition IF n'est pas exécutée, ce qui empêche l'exécution de l'instruction qui la suit.
SI 1 = 0
IMPRIMER "Première ligne"
IMPRIMER "Deuxième ligne"
La commande facultative ELSE vous permet de spécifier une instruction qui sera exécutée si la condition IF n'est pas satisfaite. Comme IF, l'instruction ELSE contrôle uniquement la commande ou le bloc de code immédiatement suivant entre BEGIN...END.
Bien que l'instruction IF semble limitée, sa clause condition peut inclure des fonctionnalités puissantes, similaires à la clause WHERE. Il s'agit en particulier d'instructions IF EXISTS().
L'expression IF EXISTS() utilise comme condition la présence de toute ligne renvoyée par l'instruction SELECT. Puisque toutes les lignes sont recherchées, la liste des colonnes de l'instruction SELECT peut être remplacée par un astérisque. Cette méthode est plus rapide que la vérification de la condition @@ROWCOUNT>0 car elle ne nécessite pas de compter le nombre total de lignes. Dès qu'au moins une ligne satisfait à la condition IF EXISTS(), la requête peut continuer à s'exécuter.
L'exemple suivant utilise l'instruction IF EXISTS pour vérifier si l'ID client 1 a des commandes avant de le supprimer de la base de données. S'il existe des informations sur au moins une commande pour ce client, la suppression n'est pas effectuée.
SI EXISTE (SELECT * FROM WHERE IdCust = 1)
IMPRIMER "Il est impossible de supprimer un client car il existe des enregistrements qui lui sont associés dans la base de données"
AUTRE
OÙ IdCust = 1
IMPRIMER "Suppression terminée avec succès"
OpérateursALORS QUE, PAUSE etCONTINUER
L'instruction WHILE dans SQL fonctionne à peu près de la même manière que dans les autres langages avec lesquels un programmeur travaille habituellement. Essentiellement, cette instruction vérifie certaines conditions avant chaque passage dans la boucle. Si, avant le prochain passage dans la boucle, la vérification de la condition donne la valeur TRUE, la boucle est parcourue, sinon l'exécution de l'instruction est terminée.
L'instruction WHILE a la syntaxe suivante :
WHILE expression booléenne
Instruction SQL I
Bloc d'instructions SQL
Bien sûr, vous pouvez utiliser l'instruction WHILE pour garantir qu'une seule instruction est exécutée dans une boucle (de la même manière qu'une instruction IF est généralement utilisée), mais en pratique, les instructions WHILE ne sont pas suivies d'un bloc BEGIN. . .END correspondant au format d’instruction complet est rare.
L'instruction BREAK vous permet de quitter immédiatement la boucle sans avoir à attendre que la fin de la boucle soit terminée et que l'expression conditionnelle soit retestée.
L'instruction CONTINUE vous permet d'interrompre une seule itération d'une boucle. L'effet de l'opérateur CONTINUE peut être brièvement décrit de telle manière qu'il assure une transition vers le début Boucle WHILE. Dès qu'une instruction CONTINUE est rencontrée dans une boucle, quel que soit son emplacement, elle revient au début de la boucle et réévalue l'expression conditionnelle (et si l'expression conditionnelle n'est plus VRAIE, la boucle se termine).
Le court script suivant illustre l'utilisation de l'instruction WHILE pour créer une boucle :
DÉCLARE @Temp int ;
RÉGLER @Temp = 0 ;
PENDANT @Temp< 3
COMMENCER
IMPRIMER @Temp ;
RÉGLER @Temp = @Temp + 1 ;
Ici, dans la boucle, la variable entière @Temp est augmentée de 0 à 3 et à chaque itération sa valeur est affichée à l'écran.
OpérateurRETOUR
L'instruction RETURN est utilisée pour arrêter l'exécution d'un lot, et donc la procédure stockée et le déclencheur (abordés dans les futurs laboratoires).