おそらく、あなたはあなたのサイトで画像をサイトにアップロードする問題にすでに遭遇しましたか? ユーザーがアバターや画像を投稿や記事にアップロードする必要があるとしましょう。 そして、画像の代わりに悪意のあるJSコードをサーバーにアップロードすることから身を守る方法は?
アップロードフォームのあるページに、フォームを挿入する必要があります。
HTMLコード
画像サイズは512Kbを超えず、ピクセルの幅は500以下、高さは1500以下です。
通常の画像アップロードフォーム。 をクリックして ダウンロード download_img.phpページに移動しました。
フォームはファイルにリンクします download_img.php。 その中で、画像の代わりに無関係なファイルをロードすることからサーバーを保護するために、ファイルサイズチェックを指定することで十分です。 画像のサイズにFALSEが返された場合、ファイルはロードされません。
PHPコード
$ uploaddir = "images /";
//これは画像が読み込まれるフォルダです
$ append = date( "YmdHis")。rand(100,1000)。"。jpg";
//これは画像に付けられる名前です
$ uploadfile = "$ uploaddir $ append";
//$uploadfile変数にはフォルダと画像名が含まれます
//この行で最も重要なことは、画像が読み込まれているかどうかを確認することです(または悪意のあるコードですか?)
//そして画像が重みで通過するかどうか。 私たちの場合、最大512 KB
if(($ _ FILES ["userfile"] ["type"] == "image / gif" || $ _FILES ["userfile"] ["type"] == "image / jpeg" || $ _FILES ["userfile "] ["type "] == "image / png")&&($ _FILES ["userfile"] ["size"]!=0および$_FILES ["userfile"] ["size"]<=512000))
{
//アップロードされたファイルの最大の重みを指定します。 現在最大512KB
if(move_uploaded_file($ _ FILES ["userfile"] ["tmp_name"]、$ uploadfile))
{
//これが画像をロードするプロセスです
$ size = getimagesize($ uploadfile);
//この関数を使用すると、画像のピクセルサイズを取得できます
if($ size< 501 && $size<1501)
{
//画像サイズが幅500ピクセル以下、高さ1500ピクセル以下の場合
echo "ファイルがロードされました。ファイルパス: http:/yoursite.ru/".$uploadfile。"";
) そうしないと (
echo "アップロードされた画像が許可された制限を超えています(幅は-500以下、高さは1500以下)";
unlink($ uploadfile);
// ファイルを削除する
}
) そうしないと (
echo"ファイルがロードされていません。戻って再試行してください";
}
) そうしないと (
echo"ファイルサイズは512Kbを超えてはなりません";
}
?>
おそらくコードは最短ではありませんが、それは仕事をします。
ご清聴ありがとうございました!
google.comを使用して検索する方法
おそらく誰もがこれを使用する方法を知っています 検索エンジン、Googleのように=)しかし、特別な構造を使用して検索クエリを正しく作成すれば、探しているものの結果をはるかに効率的かつ高速に達成できることを誰もが知っているわけではありません=)この記事では、何をどのように示すかを試みますあなたは正しく検索するために行う必要があります
Googleは、google.comで検索するときに特別な意味を持ついくつかの高度な検索演算子をサポートしています。 通常、これらの演算子は検索を変更するか、Googleにすべてを実行するように指示します。 他の種類探す。 たとえば、建設 リンク:は特別な演算子であり、クエリは リンク:www.google.com通常の検索は行われませんが、代わりにgoogle.comへのリンクがあるすべてのWebページが検索されます。
代替リクエストタイプ
キャッシュ:クエリに他の単語を含めると、Googleはキャッシュされたドキュメント内に含まれている単語を強調表示します。
例えば、 キャッシュ:www.webサイト「web」という単語が強調表示されたキャッシュコンテンツが表示されます。
リンク:上記の検索クエリは、指定されたクエリへのリンクを含むWebページを表示します。
例えば: リンク:www.website http://www.siteへのリンクがあるすべてのページが表示されます
関連している:指定されたWebページに「関連する」Webページを表示します。
例えば、 関連:www.google.com Googleのホームページに類似したWebページが一覧表示されます。
情報:情報のリクエスト:リクエストされたウェブページに関してGoogleが持っている情報を提供します。
例えば、 info:website私たちのフォーラムに関する情報が表示されます=)(Armada-アダルトウェブマスターのフォーラム)。
その他の情報要求
定義: define:クエリは、さまざまなオンラインソースからコンパイルされた、この後に入力する単語の定義を提供します。 定義は、入力されたフレーズ全体に対して行われます(つまり、正確なクエリ内のすべての単語が含まれます)。
在庫:株式を使用してクエリを開始する場合:Googleは、残りのクエリ用語を株式ティッカーシンボルとして扱い、これらのシンボルの準備された情報を示すページにリンクします。
例えば、 株式:インテルヤフー IntelとYahooに関する情報が表示されます。 (会社名ではなく、最新ニュースの文字を印刷する必要があることに注意してください)
修飾子をリクエストする
サイト:サイトを含める場合:クエリに、Googleは結果をそのドメインで検出したウェブサイトに限定します。
ru、org、comなどの個々のゾーンを検索することもできます( site:com サイト:ru)
allintitle: allintitle:を使用してクエリを実行すると、Googleはタイトルに含まれるすべてのクエリワードで結果を制限します。
例えば、 allintitle: Google検索
画像、ブログなどのすべてのGoogle検索ページを返します
タイトル:クエリにintitle:を含めると、Googleは結果をタイトルにその単語を含むドキュメントに制限します。
例えば、 タイトル:ビジネス
allinurl: allinurlを使用してクエリを実行する場合:Googleは、URL内のすべてのクエリワードで結果を制限します。
例えば、 allinurl:グーグル検索グーグルでドキュメントを返し、タイトルで検索します。 また、オプションとして、スラッシュ(/)で単語を区切ることができ、スラッシュの両側の単語が同じページ内で検索されます。例 allinurl:foo / bar
inurl:クエリにinurl:を含めると、Googleは結果をURLにその単語を含むドキュメントに制限します。
例えば、 アニメーションinurl:website
intext:ページのテキストのみで指定された単語を検索し、リンクのタイトルやテキスト、および関連しないその他のものを無視します。この修飾子の派生語もあります- allintext:それらの。 さらに、クエリ内のすべての単語はテキスト内でのみ検索されます。これも重要であり、リンクで頻繁に使用される単語は無視されます。
例えば、 intext:フォーラム
日付範囲:時間枠(daterange:2452389-2452389)で検索し、時間の日付はジュリアン形式で指定されます。
さて、そしてあらゆる種類の興味深いリクエストの例
Googleのクエリのコンパイルの例。 スパマー向け
inurl:control.guest?a = sign
Site:books.dreambook.com「ホームページURL」「Signmy」inurl:sign
サイト:www.freegb.netホームページ
Inurl:sign.asp「文字数」
「メッセージ:」inurl:sign.cfm「送信者:」
inurl:register.php「ユーザー登録」「ウェブサイト」
Inurl:edu/guestbook「ゲストブックに署名する」
Inurl:post "Post Comment" "URL"
Inurl:/ archives /「コメント:」「情報を覚えていますか?」
「スクリプトとゲストブック作成者:」「URL:」「コメント:」
inurl:?action = add“ phpBook”“ URL”
インタイトル:「新しいストーリーを送信」
雑誌
inurl:www.livejournal.com/users/mode=reply
inurl greatjournal.com/mode=reply
Inurl:fastbb.ru/re.pl?
inurl:fastbb.ru /re.pl? 「ゲストブック」
ブログ
Inurl:blogger.com/comment.g?” postID” "anonymous"
Inurl:typepad.com/「コメントを投稿する」「個人情報を覚えていますか?」
Inurl:greatestjournal.com/community/「コメントを投稿」「匿名の投稿者のアドレス」
「コメントを投稿する」「匿名の投稿者のアドレス」-
インタイトル:「コメントを投稿」
Inurl:pirillo.com「コメントを投稿」
フォーラム
Inurl:gate.html?” name = Forums”“ mode = reply”
inurl:” forum / posting.php?mode = reply”
inurl:” mes.php?”
inurl:” members.html”
inurl:forum / memberlist.php?」
Google検索エンジン(www.google.com)は、多くの検索オプションを提供します。 これらの機能はすべて、初めてのインターネットユーザーにとって非常に貴重な検索ツールであると同時に、ハッカーだけでなくコンピューター犯罪者以外の犯罪者を含む悪意のある人々の手に渡る、さらに強力な侵入と破壊の武器です。そしてテロリストさえ。
(1週間で9475ビュー)
デニス・バトランコフ
denisNOSPAMixi.ru
注意:この記事は行動のガイドではありません。 この記事は、WEBサーバーの管理者であるあなたのために書かれているので、安全であるという誤った感覚を失い、情報を取得するこの方法の陰湿さを最終的に理解し、サイトの保護に取り掛かることができます。
序章
たとえば、0.14秒で1670ページが見つかりました。
2. たとえば、別の行を入力してみましょう。
inurl: "auth_user_file.txt"少し少ないですが、これは無料ダウンロードとパスワードの推測(同じJohn The Ripperを使用)にはすでに十分です。 以下にいくつかの例を示します。
したがって、Google検索エンジンがほとんどのインターネットサイトにアクセスし、そこに含まれる情報をキャッシュしていることを理解する必要があります。 このキャッシュされた情報を使用すると、サイトに直接接続しなくても、Googleによって内部に保存されている情報を掘り下げるだけで、サイトとサイトのコンテンツに関する情報を取得できます。 さらに、サイト上の情報が利用できなくなった場合でも、キャッシュ内の情報は保持される可能性があります。 この方法に必要なのは、いくつかを知ることだけです キーワードグーグル。 この手法はGoogleハッキングと呼ばれます。
Googleハッキングに関する情報が3年前に初めてBugtruckメーリングリストに掲載されました。 2001年に、このトピックはフランスの学生によって提起されました。 この手紙へのリンクは次のとおりですhttp://www.cotse.com/mailing-lists/bugtraq/2001/Nov/0129.html。 このようなリクエストの最初の例を示します。
1)/adminのインデックス
2)/passwordのインデックス
3)/mailのインデックス
4)インデックス/ + banques + filetype:xls(フランスの場合...)
5)/+passwdのインデックス
6)/password.txtのインデックス
このトピックは、ごく最近、インターネットの英語を読む部分で多くの騒ぎを引き起こしました。2004年5月7日に公開されたJohnnyLongによる記事の後です。 Googleハッキングのより完全な研究については、この著者のサイトhttp://johnny.ihackstuff.comにアクセスすることをお勧めします。 この記事では、あなたを最新の状態にしたいと思います。
誰がそれを使うことができますか:
-ジャーナリスト、スパイ、および他の人のビジネスに鼻を突っ込むのが好きなすべての人は、これを使用して妥協的な証拠を検索できます。
-ハッキングに適したターゲットを探しているハッカー。
Googleの仕組み。
会話を続けるために、Googleクエリで使用されているキーワードのいくつかを思い出させてください。
+記号を使用して検索
グーグルは、その意見では、重要でない単語を検索から除外します。 たとえば、英語の疑問詞、前置詞、冠詞:たとえば、of、where。 ロシア語では、Googleはすべての単語を重要と見なしているようです。 単語が検索から除外されている場合、Googleはそれについて書き込みます。 Googleがこれらの単語を含むページの検索を開始するには、単語の前にスペースを入れずに、ページの前に+記号を追加する必要があります。 例えば:
ベースのエース+
サインで検索-
Googleが見つけた場合 たくさんの特定のトピックを含むページを除外するページでは、特定の単語を含まないページのみを検索するようにGoogleに強制することができます。 これを行うには、単語の前にスペースを入れずに、それぞれの前に記号を付けてこれらの単語を示す必要があります。 例えば:
釣り-ウォッカ
〜記号で検索
指定された単語だけでなく、その同義語も検索することをお勧めします。 これを行うには、単語の前に記号〜を付けます。
検索 正確なフレーズ二重引用符を使用する
Googleは、クエリ文字列に書き込んだ単語のすべての出現箇所を各ページで検索します。単語の相対的な位置は関係ありません。主なことは、指定されたすべての単語が同時にページ上にあることです(これがデフォルトのアクションです)。 正確なフレーズを見つけるには、引用符で囲む必要があります。 例えば:
「ブックエンド」
指定されたワードの少なくとも1つを使用するには、論理演算を明示的に指定する必要があります:OR。 例えば:
本の安全性または保護
さらに、検索文字列の*記号を使用して、任意の単語とを示すことができます。 任意の文字を表します。
追加の演算子を使用して単語を検索する
検索文字列に次の形式で指定されている検索演算子があります。
演算子:search_term
コロンの横のスペースは必要ありません。 コロンの後にスペースを挿入すると、エラーメッセージが表示され、その前に、Googleはそれらを通常の検索文字列として使用します。
追加の検索演算子のグループがあります:言語-結果を表示する言語を示します、日付-過去3、6、または12か月の結果を制限します、発生-ドキュメント内のどこを探す必要があるかを示します文字列:すべての場所、タイトル、URL、ドメイン-指定されたサイトを検索する、またはその逆の場合、検索から除外します。セーフサーチ-指定されたタイプの情報を含むサイトをブロックし、検索結果ページから削除します。
ただし、一部の演算子は追加のパラメーターを必要としません。たとえば、クエリ「 キャッシュ:www.google.com「完全な検索文字列として呼び出すことができますが、逆に、一部のキーワードでは検索語が必要です。たとえば、」 サイト:www.google.comヘルプ"。私たちのトピックに照らして、次の演算子を見てみましょう。
オペレーター |
説明 |
追加のパラメータが必要ですか? |
search_termで指定されたサイトのみを検索します |
||
タイプがsearch_termのドキュメントのみを検索する |
||
タイトルにsearch_termを含むページを検索する |
||
タイトルにsearch_termという単語がすべて含まれているページを検索する |
||
アドレスにsearch_termという単語が含まれているページを検索する |
||
アドレスにsearch_termという単語がすべて含まれているページを検索する |
オペレーター サイト:指定したサイトでのみ検索を制限し、ドメイン名だけでなくIPアドレスも指定できます。 たとえば、次のように入力します。
オペレーター ファイルタイプ:検索を特定のタイプのファイルに制限します。 例えば:
この記事の日付の時点で、Googleは13の異なるファイル形式内で検索できます。
- Adobe Portable Document Format(pdf)
- Adobe PostScript(ps)
- Lotus 1-2-3(wk1、wk2、wk3、wk4、wk5、wki、wks、wku)
- Lotus Word Pro(lwp)
- MacWrite(mw)
- マイクロソフトエクセル(xls)
- Microsoft PowerPoint(ppt)
- Microsoft Word(doc)
- Microsoft Works(wks、wps、wdb)
- Microsoft Write(wri)
- リッチテキスト形式(rtf)
- Shockwaveフラッシュ(swf)
- テキスト(ans、txt)
オペレーター リンク:指定されたページを指すすべてのページを表示します。
インターネット上のいくつの場所があなたについて知っているかを見るのは常に興味深いはずです。 私たちは試してみます:
オペレーター キャッシュ:は、Googleが最後にページにアクセスしたときに表示されたサイトのGoogleキャッシュバージョンを示しています。 頻繁に変更されるサイトを取り上げて、次のように確認します。
オペレーター タイトル:ページタイトルで指定された単語を検索します。 オペレーター allintitle:は拡張機能です。ページタイトルで指定されたすべての単語を検索します。 比較:
intitle:火星への飛行
intitle:flight intitle:on intitle:mars
allintitle:火星への飛行
オペレーター inurl:指定された文字列をURLに含むすべてのページをGoogleに表示させます。 allinurl:URL内のすべての単語を検索します。 例えば:
allinurl:acid_stat_alerts.php
このコマンドは、SNORTを持っていない人にとって特に便利です。少なくとも、実際のシステムでどのように機能するかを確認できます。
Googleハッキング方法
そこで、上記の演算子とキーワードを組み合わせることで、誰でも必要な情報を収集し、脆弱性を検索できることがわかりました。 これらの手法は、Googleハッキングと呼ばれることがよくあります。
サイトの地図
site:ステートメントを使用して、Googleがサイトで見つけたすべてのリンクを表示できます。 通常、スクリプトによって動的に作成されるページはパラメーターを使用してインデックス付けされないため、一部のサイトではISAPIフィルターを使用して、リンクがフォームに含まれないようにします。 /article.asp?num=10&dst=5、ただしスラッシュ付き / article / abc / num / 10 / dst / 5。 これは、サイトが一般的に検索エンジンによってインデックス付けされることを保証するために行われます。
やってみよう:
サイト:www.whitehouse.govホワイトハウス
Googleは、サイトのすべてのページにホワイトハウスという単語が含まれていると考えています。 これは、すべてのページを取得するために使用するものです。
簡略化されたバージョンもあります。
サイト:whitehouse.gov
そして最良の部分は、whitehouse.govの仲間が、私たちが彼らのサイトの構造を調べ、Googleが自分自身のためにダウンロードしたキャッシュされたページを調べたことさえ知らなかったことです。 これは、当面気付かれることなく、サイトの構造を調べたり、コンテンツを表示したりするために使用できます。
ディレクトリ内のファイルの一覧表示
WEBサーバーは、通常の代わりにサーバーディレクトリのリストを表示できます HTMLページ。 これは通常、ユーザーに特定のファイルを選択してダウンロードするように強制するために行われます。 ただし、多くの場合、管理者はディレクトリの内容を表示するつもりはありません。 これは、サーバーの構成ミスまたはディレクトリにマスターページがないことが原因です。 その結果、ハッカーはディレクトリ内で何か面白いものを見つけて、それを自分の目的に使用する機会があります。 そのようなすべてのページを見つけるには、それらすべてに単語が含まれていることに注意するだけで十分です:タイトルにインデックス。 しかし、単語のインデックスにはそのようなページだけが含まれていないため、クエリを絞り込み、ページ自体のキーワードを考慮する必要があります。したがって、クエリは次のようになります。
親ディレクトリのintitle:index.of
intitle:index.of名前のサイズ
ほとんどのディレクトリリストは意図的なものであるため、最初に置き忘れたリストを見つけるのに苦労するかもしれません。 ただし、少なくとも、以下で説明するように、リストを使用してWEBサーバーのバージョンを判別することができます。
WEBサーバーのバージョンを取得しています。
ハッカーの攻撃を開始する前に、WEBサーバーのバージョンを知ることは常に役立ちます。 再びグーグルのおかげで、サーバーに接続せずにこの情報を取得することが可能です。 ディレクトリリストを注意深く見ると、WEBサーバーの名前とそのバージョンがそこに表示されていることがわかります。
Apache1.3.29-trf296.free.frポート80のProXadサーバー
経験豊富な管理者はこの情報を変更できますが、原則としてそれは真実です。 したがって、この情報を取得するには、リクエストを送信するだけで十分です。
intitle:index.of server.at
特定のサーバーの情報を取得するために、リクエストを絞り込みます。
intitle:index.of server.at site:ibm.com
またはその逆に、特定のバージョンのサーバーで実行されているサーバーを探しています。
intitle:index.of Apache/2.0.40サーバー
この手法は、ハッカーが被害者を見つけるために使用できます。 たとえば、彼が特定のバージョンのWEBサーバーのエクスプロイトを持っている場合、彼はそれを見つけて既存のエクスプロイトを試すことができます。
また、新しいバージョンのWEBサーバーをインストールするときにデフォルトでインストールされるページを確認して、サーバーのバージョンを取得することもできます。 たとえば、Apache 1.2.6のテストページを表示するには、次のように入力します。
intitle:Test.Page.for.Apache it.worked!
また、一部 オペレーティングシステムインストール中に、彼らはすぐにWEBサーバーをインストールして起動します。 ただし、一部のユーザーはこれに気づいていません。 当然、誰かがデフォルトページを削除していないことがわかった場合は、コンピューターがまったく構成されておらず、おそらく攻撃に対して脆弱であると想定するのが論理的です。
IIS5.0ページを探してみてください
allintitle:Windows2000インターネットサービスへようこそ
IISの場合、サーバーのバージョンだけでなく、サーバーのバージョンも判別できます。 Windows版およびサービスパック。
WEBサーバーのバージョンを確認する別の方法は、デフォルトでサイトにインストールできるマニュアル(ヘルプページ)と例を探すことです。 ハッカーは、これらのコンポーネントを使用してサイトへの特権アクセスを取得する方法を数多く見つけました。 そのため、本番サイトでこれらのコンポーネントを削除する必要があります。 これらのコンポーネントが存在することで、サーバーのタイプとそのバージョンに関する情報を取得できることは言うまでもありません。 たとえば、apacheのマニュアルを見つけましょう。
inurl:manualapacheディレクティブモジュール
GoogleをCGIスキャナーとして使用する。
CGIスキャナーまたはWEBスキャナーは、被害者のサーバー上の脆弱なスクリプトやプログラムを検索するためのユーティリティです。 これらのユーティリティは、何を探すべきかを知る必要があります。このため、脆弱なファイルの全リストがあります。たとえば、次のようになります。
/cgi-bin/cgiemail/uargg.txt
/random_banner/index.cgi
/random_banner/index.cgi
/cgi-bin/mailview.cgi
/cgi-bin/maillist.cgi
/cgi-bin/userreg.cgi
/iissamples/ISSamples/SQLQHit.asp
/SiteServer/admin/findvserver.asp
/scripts/cphost.dll
/cgi-bin/finger.cgi
これらの各ファイルは、Googleを使用して検索できます。さらに、検索バーのファイル名にindex ofまたはinurlという単語を使用して検索できます。たとえば、脆弱なスクリプトを含むサイトを検索できます。
allinurl:/random_banner/index.cgi
追加の知識があれば、ハッカーはスクリプトの脆弱性を悪用し、その脆弱性を利用して、サーバーに保存されているファイルをスクリプトに強制的に提供させることができます。 たとえば、パスワードファイル。
Googleによるハッキングから身を守る方法。
1.重要なデータをWEBサーバーにアップロードしないでください。
データを一時的に投稿した場合でも、忘れてしまう可能性があります。そうしないと、誰かがこのデータを見つけて取得してから消去することになります。 しないでください。 盗難からデータを保護するデータを転送する方法は他にもたくさんあります。
2.サイトを確認します。
説明されている方法を使用して、サイトを調査します。 サイトhttp://johnny.ihackstuff.comに表示される新しいメソッドについて、サイトを定期的に確認してください。 アクションを自動化する場合は、Googleから特別な許可を得る必要があることに注意してください。 注意深く読んだら http://www.google.com/terms_of_service.html、次に、次のフレーズが表示されます。Googleからの事前の明示的な許可なしに、いかなる種類の自動クエリをGoogleのシステムに送信することはできません。
3.サイトまたはその一部をインデックスに登録するためにGoogleを必要としない場合があります。
Googleでは、サイトまたはその一部へのリンクをデータベースから削除したり、キャッシュからページを削除したりすることができます。 さらに、サイトでの画像の検索を禁止したり、検索結果にページの短い断片を表示したりすることを禁止することができます。サイトを削除するためのすべての可能性がページに記載されています http://www.google.com/remove.html。 これを行うには、あなたが本当にこのサイトの所有者であることを確認するか、ページにタグを挿入する必要があります。
4.robots.txtを使用します
検索エンジンはサイトのルートにあるrobots.txtファイルを調べ、単語でマークされた部分にインデックスを付けないことが知られています 禁止する。 これを使用して、サイトの一部がインデックスに登録されないようにすることができます。 たとえば、サイト全体のインデックスを作成しないようにするには、次の2行を含むrobots.txtファイルを作成します。
ユーザーエージェント: *
禁止:/
他に何が起こるか
人生があなたにとってはちみつのように見えないように、私は最後に、上記の方法を使用して、スクリプトとWEBサーバーの穴を探す人々をフォローしているサイトがあると言います。 そのようなページの例は
付録。
少し甘い。 次のいずれかを自分で試してください。
1. #mysql dump filetype:sql-mySQLデータベースダンプを検索します
2.ホストの脆弱性の概要レポート-他の人が見つけた脆弱性を表示します
3. inurl:main.phpで実行されているphpMyAdmin-これにより、phpmyadminパネルを介してコントロールが強制的に閉じられます
4.機密配布用ではありません
5.リクエストの詳細コントロールツリーサーバー変数
6.子モードで実行する
7.このレポートはWebLogによって生成されました
8. intitle:index.of cgiirc.config
9. filetype:conf inurl:firewall -intitle:cvs-誰かがファイアウォール構成ファイルを必要としているのではないでしょうか。 :)
10. intitle:index.offinances.xls-うーん...。
11. intitle:dbconvert.exeチャットのインデックス-icqチャットログ
12. intext:TobiasOetikerトラフィック分析
13. intitle:Webalizerによって生成された使用統計
14. intitle:高度なWeb統計の統計
15. intitle:index.of ws_ftp.ini-ws ftp config
16. inurl:ipsec.secretsは共有秘密を保持します-秘密鍵-良い発見
17. inurl:main.phpphpMyAdminへようこそ
18. inurl:server-infoApacheサーバー情報
19.サイト:edu管理者グレード
20. ORA-00921:SQLコマンドの予期しない終了-パスの取得
21. intitle:index.of trillian.ini
22. intitle:pwd.dbのインデックス
23. intitle:index.of people.lst
24. intitle:index.of master.passwd
25.inurl:passlist.txt
26. intitle:.mysql_historyのインデックス
27. intitle:intext:globals.incのインデックス
28. intitle:index.ofadministrators.pwd
29. intitle:Index.of etc shadow
30. intitle:index.of secring.pgp
31. inurl:config.php dbuname dbpass
32. inurl:perform filetype:ini
トレーニングセンター「Informzaschita」http://www.itsecurity.ru-情報セキュリティトレーニングの分野における主要な専門センター(モスクワ教育委員会のライセンスNo. 015470、州の認定No. 004251)。 ロシアとCIS諸国で唯一認可されたインターネットセキュリティシステムズとクリアスウィフトのトレーニングセンター。 マイクロソフト認定トレーニングセンター(セキュリティスペシャライゼーション)。 トレーニングプログラムは、ロシア国家技術委員会FSB(FAPSI)と調整されています。 高度なトレーニングに関するトレーニングの証明書と州の文書。
SoftKeyは、バイヤー、開発者、ディーラー、アフィリエイトパートナー向けのユニークなサービスです。 さらに、これはロシア、ウクライナ、カザフスタンで最高のオンラインソフトウェアストアの1つであり、顧客に幅広い、多くの支払い方法、迅速な(多くの場合即時の)注文処理、個人セクションでの注文履行プロセスの追跡、さまざまな割引を提供します店とメーカーからON。
プライベートデータを受信することは、必ずしもハッキングを意味するわけではありません。パブリックドメインで公開されることもあります。 Googleの設定と少しの工夫を知っていると、クレジットカード番号からFBI文書まで、多くの興味深いものを見つけることができます。
警告
すべての情報は、情報提供のみを目的として提供されています。 編集者も著者も、この記事の資料によって引き起こされる可能性のある危害について責任を負いません。今日、すべてがインターネットに接続されており、アクセスの制限についてはほとんど気にかけていません。 したがって、多くの個人データが検索エンジンの餌食になります。 スパイダーロボットはWebページに限定されなくなりましたが、Webで利用可能なすべてのコンテンツにインデックスを付け、データベースに機密情報を絶えず追加しています。 これらの秘密を学ぶのは簡単です-あなたはそれらについて尋ねる方法を知る必要があるだけです。
ファイルを探す
グーグルは有能な手で、個人情報や公式使用のためのファイルなど、ウェブ上で悪いものすべてをすばやく見つけます。 多くの場合、それらは敷物の下に鍵のように隠されています。実際のアクセス制限はなく、データはサイトの裏側にあり、リンクはリンクされていません。 標準のGoogleWebインターフェースは、基本的な高度な検索設定のみを提供しますが、これらでも十分です。
Google検索を特定のタイプのファイルに制限するために使用できる演算子は、filetypeとextの2つです。 1つ目は、検索エンジンがファイルヘッダーによって決定する形式を設定し、2つ目は、内部コンテンツに関係なく、ファイル拡張子を設定します。 どちらの場合も検索する場合は、拡張子のみを指定する必要があります。 当初、ext演算子は、ファイルに特定の形式特性がない場合に使用すると便利でした(たとえば、iniおよびcfg構成ファイルを検索する場合、その中には何でも含めることができます)。 現在、Googleのアルゴリズムが変更されており、演算子間に目に見える違いはありません。ほとんどの場合、結果は同じです。

出力のフィルタリング
デフォルトでは、Googleは単語を検索し、一般に、インデックス付きページのすべてのファイルに入力されている文字を検索します。 トップレベルドメイン、特定のサイト、またはファイル自体の目的のシーケンスの場所によって、検索範囲を制限できます。 最初の2つのオプションでは、siteステートメントが使用され、その後にドメイン名または選択したサイトが続きます。 3番目のケースでは、演算子のセット全体を使用して、サービスフィールドとメタデータの情報を検索できます。 たとえば、allinurlは、リンク自体の本文で指定されたallinanchorを、タグとともに提供されるテキストで検索します。 、allintitle-ページヘッダー内、allintext-ページ本文内。
演算子ごとに、名前が短い(接頭辞allなしの)軽量バージョンがあります。 違いは、allinurlはすべての単語のリンクを検索するのに対し、inurlは最初の単語のリンクのみを検索することです。 クエリの2番目以降の単語は、Webページのどこにでも表示できます。 inurl演算子も、同様の意味を持つ別の演算子(site)とは異なります。 1つ目は、目的のドキュメント(/ cgi-bin /など)へのリンク内の任意の文字シーケンスを検索することもできます。これは、既知の脆弱性を持つコンポーネントを検索するために広く使用されています。
実際に試してみましょう。 allintextフィルターを使用して、クレジットカード番号と確認コードのリストをクエリに返すようにします。これらのリストは2年後(または所有者が全員に連続して餌をやるのに飽きたとき)にのみ有効期限が切れます。
Allintext:カード番号の有効期限/ 2017 cvv 
若いハッカーが国防総省やNASAの「サーバーに侵入」し、機密情報を盗んだというニュースを読んだとき、ほとんどの場合、それはまさにGoogleを使用するこの基本的な手法です。 NASAの従業員のリストとその連絡先の詳細に関心があるとします。 確かにそのようなリストは電子形式です。 便宜上、または見落としのために、組織のWebサイト自体にある場合もあります。 この場合、内部使用を目的としているため、参照がないことは論理的です。 そのようなファイルにはどのような単語を含めることができますか? 少なくとも-フィールド「アドレス」。 これらすべての仮定をテストするのは簡単です。

inurl:nasa.gov filetype:xlsx "address"

官僚制を利用しています
そのような発見は楽しい些細なことです。 本当に確かなキャッチは、Googleウェブマスターオペレーター、ウェブ自体、そしてあなたが探しているものの構造についてのより詳細な知識から来ています。 詳細がわかれば、出力を簡単にフィルタリングし、必要なファイルのプロパティを調整して、残りのデータで本当に価値のあるデータを取得できます。 ここで官僚機構が救助に来るのはおかしいです。 これは、誤ってWebに漏洩した秘密情報を検索するのに便利な典型的な定式化を生成します。
たとえば、米国国防総省のオフィスで義務付けられている配布ステートメントスタンプは、ドキュメントの配布に対する標準化された制限を意味します。 文字Aは、秘密が何もない公開リリースを示します。 B-内部使用のみを目的とし、C-厳密に機密であり、Fまでなど。これとは別に、最高レベルの国家機密を表す特に価値のある情報を示す文字Xがあります。 勤務中にそれを行うことになっている人にそのような文書を探してもらい、文字Cのファイルに限定します。DoDI5230.24によると、そのようなマーキングは、輸出管理下にある重要な技術の説明を含む文書に割り当てられます。 このような慎重に保護された情報は、米陸軍に割り当てられた.milトップレベルドメインのサイトで見つけることができます。
「配布ステートメントC」inurl:navy.mil 
米国国防総省とその契約組織のサイトのみが.milドメインに収集されると非常に便利です。 ドメイン限定の検索結果は非常にクリーンであり、タイトルはそれ自体を物語っています。 この方法でロシアの秘密を検索することは実際には無意味です。カオスは.ruおよび.rfドメインで支配され、多くの兵器システムの名前は植物(PP "Kiparis"、自走砲 "Acacia")またはさらには素晴らしい(TOS「ピノキオ」)。

.milドメイン内のサイトのドキュメントを注意深く調べることで、他のマーカーを確認して検索を絞り込むことができます。 たとえば、興味深い技術情報を検索するのにも便利な輸出制限「Sec2751」への参照。 かつて表示されていた公式サイトから削除されることがあるため、検索結果で興味深いリンクをたどることができない場合は、Googleキャッシュ(キャッシュ演算子)またはインターネットアーカイブのウェブサイトを使用してください。
雲に登る
政府機関からの誤って機密解除されたドキュメントに加えて、Dropboxやその他のデータストレージサービスからの個人ファイルへのリンクが、公開されたデータへの「プライベート」リンクを作成する場合があります。 代替の自作サービスではさらに悪化します。 たとえば、次のクエリは、FTPサーバーがインストールされており、ルーターでルーターをアクティブに使用しているすべてのVerizonクライアントのデータを検索します。
Allinurl:ftp://verizon.net
現在、そのような賢い人々は4万人を超えており、2015年の春には1桁多くなりました。 Verizon.netの代わりに、有名なプロバイダーの名前に置き換えることができます。有名なプロバイダーほど、漁獲量を増やすことができます。 内蔵のFTPサーバーを介して、ルーターに接続された外付けドライブ上のファイルを表示できます。 通常、これはリモートワーク用のNAS、パーソナルクラウド、またはある種のピアツーピアファイルダウンロードです。 このようなメディアのすべてのコンテンツは、Googleやその他の検索エンジンによってインデックスが作成されるため、直接リンクを介して外部ドライブに保存されているファイルにアクセスできます。

設定の覗き見
クラウドへの大規模な移行の前は、脆弱性も欠いていた単純なFTPサーバーがリモートストレージとして支配されていました。 それらの多くは今日でも関連しています。 たとえば、人気のあるWS_FTP Professionalプログラムは、構成データ、ユーザーアカウント、およびパスワードをws_ftp.iniファイルに保存します。 すべてのエントリはプレーンテキストで保存され、パスワードは最小限の難読化の後にTriple DESアルゴリズムを使用して暗号化されるため、簡単に見つけて読むことができます。 ほとんどのバージョンでは、最初のバイトを破棄するだけで十分です。

このようなパスワードの復号化は、WS_FTPPasswordDecryptorユーティリティまたは無料のWebサービスを使用して簡単に行えます。

任意のサイトのハッキングについて話すとき、それらは通常、CMS構成ファイルまたはアプリケーションのログとバックアップからパスワードを取得することを意味します eコマース。 それらの典型的な構造を知っていれば、キーワードを簡単に示すことができます。 ws_ftp.iniにあるような行は非常に一般的です。 たとえば、DrupalとPrestaShopには常にユーザーID(UID)と対応するパスワード(pwd)があり、すべての情報は.inc拡張子の付いたファイルに保存されます。 次のように検索できます。
"pwd =" "UID =" ext:inc
DBMSからパスワードを公開します
SQLサーバーの構成ファイルで、名前とアドレス Eメールユーザーはクリアテキストで保存され、パスワードの代わりにMD5ハッシュが書き込まれます。 厳密に言えば、それらを復号化することは不可能ですが、既知のハッシュとパスワードのペアの中で一致するものを見つけることができます。

これまで、パスワードハッシュさえ使用しないDBMSがあります。 それらのいずれかの構成ファイルは、ブラウザーで簡単に表示できます。
Intext:DB_PASSWORD filetype:env

の出現で Windowsサーバー構成ファイルの場所は、レジストリによって部分的に占有されていました。 ファイルタイプとしてregを使用すると、まったく同じ方法でブランチを検索できます。 たとえば、次のようになります。
Filetype:regHKEY_CURRENT_USER"パスワード"=
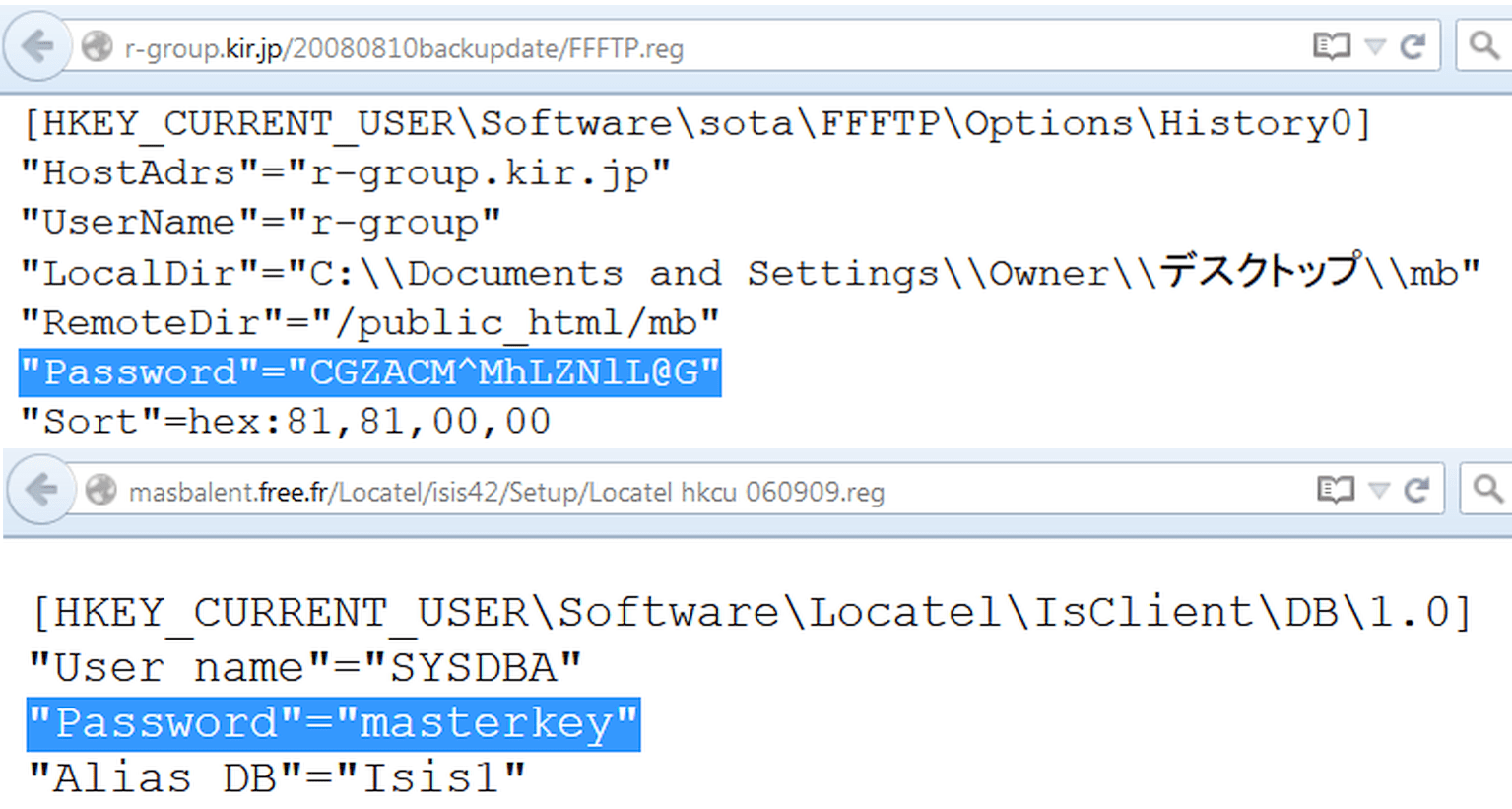
明らかなことを忘れないでください
Googleが誤って開いて取得したデータを使用して、機密情報を取得できる場合があります。 理想的なオプションは、いくつかの一般的な形式でパスワードのリストを見つけることです。 アカウント情報をテキストファイル、Word文書、または電子メールに保存します エクセルスプレッドシート絶望的な人々だけがそうすることができます、しかし彼らは常に十分です。
Filetype:xls inurl:password

一方では、そのような事件を防ぐための多くの手段があります。 htaccessで適切なアクセス権を指定し、CMSにパッチを適用し、左側のスクリプトを使用せず、他の穴を閉じる必要があります。 また、robots.txt除外リストを含むファイルがあり、検索エンジンがその中で指定されたファイルとディレクトリにインデックスを付けることを禁止しています。 一方、一部のサーバーのrobots.txt構造が標準の構造と異なる場合、サーバーに何を隠そうとしているのかがすぐに明らかになります。

任意のサイトのディレクトリとファイルのリストの前に、の標準的な碑文インデックスがあります。 サービス目的でタイトルに表示する必要があるため、検索をintitle演算子に限定することは理にかなっています。 興味深いものは、/ admin /、/ personal /、/ etc /、さらには/secret/ディレクトリにあります。

更新に従ってください
ここでは関連性が非常に重要です。古い脆弱性は非常にゆっくりと閉じられますが、Googleとその検索結果は常に変化しています。 「最後の1秒」フィルター(リクエストURLの最後の&tbs = qdr:s)と「リアルタイム」フィルター(&tbs = qdr:1)の間にも違いがあります。
日付の期間 最新のアップデート Googleのファイルも暗黙的に示されます。 グラフィカルなWebインターフェイスを介して、一般的な期間(時間、日、週など)のいずれかを選択したり、日付範囲を設定したりできますが、この方法は自動化には適していません。
アドレスバーの外観から、&tbs = qdr:構文を使用して結果の出力を制限する方法についてのみ推測できます。 1年の制限を指定した後の文字y(&tbs = qdr:y)、mは先月の結果、wは週、dは過去の日、hは最後の時間、nは分、とsは私に秒を与えます。 Googleに通知されたばかりの最新の結果は、&tbs = qdr:1フィルターを使用して検出されます。
トリッキーなスクリプトを作成する必要がある場合は、日付範囲がGoogleで日付範囲演算子を使用してジュリアン形式で設定されていることを知っておくと便利です。 たとえば、これは、2015年1月1日から7月1日までにアップロードされた機密という単語を含むPDFドキュメントのリストを見つける方法です。
機密ファイルタイプ:pdf日付範囲:2457024-2457205
範囲は、小数点なしのユリウス日形式で指定されます。 グレゴリオ暦から手動で翻訳するのは不便です。 日付コンバーターを使用する方が簡単です。
再度ターゲティングとフィルタリング
検索クエリで追加の演算子を指定することに加えて、それらをリンク本文で直接送信することもできます。 たとえば、filetype:pdfトレイトはas_filetype=pdfコンストラクトに対応します。 したがって、説明を設定すると便利です。 ホンジュラス共和国からの結果のみの出力が、検索URLに構文cr = countryHNを追加することによって設定されているとしましょう。ただし、バブルイスク市からのみです-gcs=Bobruisk。 の完全なリストについては、開発者のセクションを参照してください。
Googleの自動化ツールは、生活を楽にするように設計されていますが、多くの場合、面倒な作業になります。 たとえば、ユーザーの都市は、WHOISを介したユーザーのIPによって決定されます。 この情報に基づいて、Googleはサーバー間の負荷を分散するだけでなく、検索結果も変更します。 地域によっては、同じクエリで最初のページに異なる結果が表示され、一部が完全に非表示になる場合があります。 コスモポリタンのように感じて、どの国からの情報を検索しても、ディレクティブgl=countryの後の2文字のコードに役立ちます。 たとえば、オランダのコードはNLですが、バチカンと北朝鮮はGoogleに独自のコードを持っていません。
多くの場合、いくつかの高度なフィルターを使用した後でも、検索結果が散らかっています。 この場合、いくつかの例外単語を追加することでクエリを簡単に絞り込むことができます(それぞれの前にマイナス記号が付きます)。 たとえば、銀行、名前、チュートリアルは、個人という言葉でよく使用されます。 したがって、よりクリーンな検索結果には、クエリの教科書の例ではなく、洗練された例が表示されます。
Intitle: "Index of / Personal /" -names -tutorial -banking
最後の例
洗練されたハッカーは、必要なものをすべて自分で提供するという事実が特徴です。 たとえば、VPNは便利なものですが、高価または一時的であり、制限があります。 一人でサインアップするのは高額です。 グループサブスクリプションがあるのは良いことです、そしてグーグルの助けを借りてそれはグループの一部になるのは簡単です。 これを行うには、Cisco VPN設定ファイルを見つけます。このファイルには、かなり非標準のPCF拡張子があり、認識可能なパスがあります:Program Files \ Cisco Systems \ VPN Client\Profiles。 1つのリクエストで、たとえばボン大学のフレンドリーなスタッフに参加します。
ファイルタイプ:pcfvpnまたはグループ

情報
Googleはパスワード付きの構成ファイルを見つけますが、それらの多くは暗号化されているか、ハッシュに置き換えられています。 固定長の文字列が表示された場合は、すぐに復号化サービスを探してください。パスワードは暗号化された形式で保存されますが、Maurice Massardはすでにパスワードを復号化するプログラムを作成しており、campusgeeks.comから無料で提供しています。
Googleの助けを借りて、何百もの異なるタイプの攻撃と侵入テストが実行されます。 のための多くのオプションがあります 人気番組、主要なデータベース形式、PHP、クラウドなどの多数の脆弱性。 探しているものを正確に知ることで、必要な情報(特に公開するつもりのない情報)を簡単に入手できます。 Shodanは興味深いアイデアを提供するだけでなく、インデックス付きネットワークリソースのデータベースも提供します。